At Small Improvements, we are always keen to learn about our customers and how we can make the product better for them. Speaking to customers is great (and we do it all the time) but using the data we hold to find trends and usage patterns helps to find things that the customer won’t tell you. For example, we were able to tell that most people add the talking points for their 1:1 Meetings within the first 10 minutes of creating the Meeting. Using this knowledge we de-emphasized the concept of Drafts in 1:1 Meetings (most people are ready to add talking points at the time they create the 1:1 Meeting).
All our teams (Product, Marketing, Engineering) regularly ask questions like “How many customers use feature X?”, “What’s the average length of a Performance Review?” or “Are there common 360 Feedback cycle creation dates?”. We’ve got questions coming left, right and center but how do we answer all of them?
In the early days, one of the development team would have to trawl through our database themselves to determine the answer. This is slow and tedious so we built a framework that would help automate the process of sifting through the data. Developers could now write Map-Reduce jobs, using common snippets that others had created to do complex analysis of our data. This process worked fine but we simply weren’t able to answers all questions in a timely manner. The problem was writing the code was only half the task, it then required deploying to a server with access to our database to do its number crunching. If something was wrong with the code, the whole process had to start again.
Building an MVP
A few of us had worked for companies previously who used a so-called “Data Warehouse”. The idea is to regularly export your data, convert it to a structure that is optimized for data analysis and import it into a separate database. This means that anyone with access to the database can query it (using SQL or a specialized tool) to answer questions like “How many companies use feature X?”. We thought we’d use our slack time (we are encouraged to take up to 20% of our time to work on side-projects that benefit the company) and see if we could build something.
A production database is usually not the most performant for analytics queries. The schemas are generally optimized for the application running on top of them and not for all-encompassing searches. Ours is no different and we quickly decided we needed to get the data into something built for the task. Luckily, our database Google Datastore has the ability to export data very easily. As our data is Document-Oriented, we initially planned to use another Document database like MongoDB. We had the beginnings of a plan; export the data out of the Datastore, import it into MongoDB. The first drawback was that format of the exports, Google uses a custom LevelDB format. There’s not much information about converting this format into something useful but we did find this Github repo.
Our first prototype Java app for reading a Datastore backup looked something like this;
- Download a backup from a Google Cloud Storage bucket
- Read the data into Java objects (using the Google Cloud SDK)
- Convert those objects into (id and fields) into JSON documents
- Insert the JSON documents into MongoDB

The second iteration
With this first prototype, we were able to recreate the Map-Reduce tasks we had run using our own Framework for using the MongoDB Map-Reduce framework. This was a great first step, but what we really wanted was something that:
- Was easy to use by anyone in the company, not just developers (writing code should not be required)
- Queries should be fast to write (and return results quickly)
- Was anonymized (GDPR is in force now, we don’t want to give anyone access to any personal data)
With these new goals in mind, we set about working on phase 2. We realized that NoSql was perhaps not the friendliest format for our data warehouse. If we wanted everyone to be able to query it, we really needed something that could run SQL. We came across Google BigQuery, it is able to ingest data formatted in JSON or CSV and the resulting data can be queried using standard SQL. This is great for us as we don’t need to perform any special mapping to convert our JSON objects to something a regular relational database can handle (BigQuery does all that for you). We gave it a try with some sample data and everything worked. BigQuery can actually process data directly from the Datastore but we needed to do some transformation in order to fix our goal of making the data anonymous. For that, we adjusted our code from the original prototype.
Current Architecture
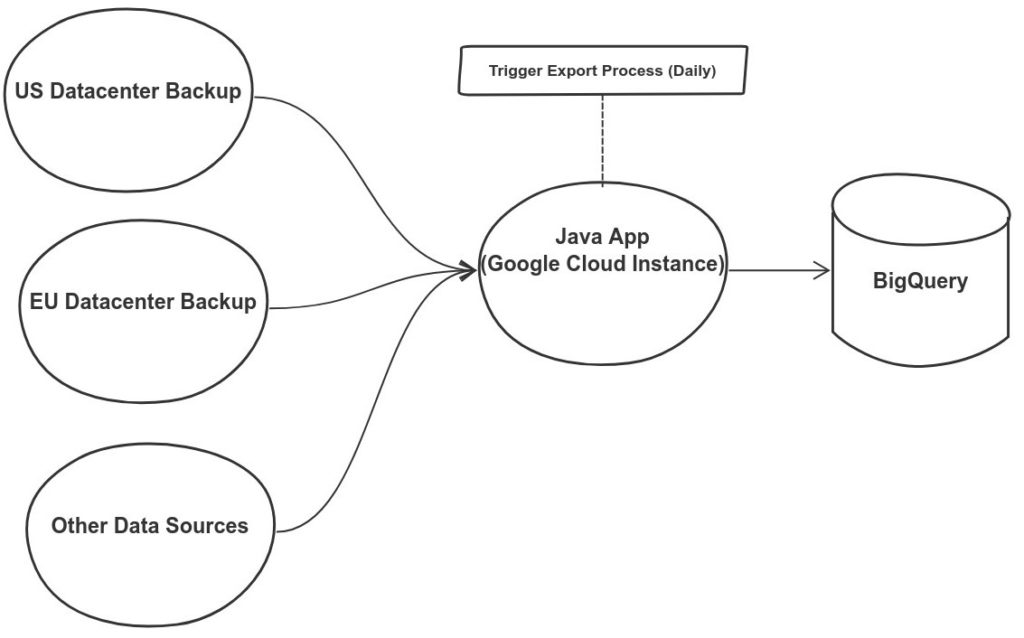
Here’s the new process (currently running daily):
- Backup Datastore to CloudStorage
- Run Java job to anonymize and normalize data (e.g. data spread across multiple entities/tables can be combined into one)
- Export new data as JSON to BigQuery (overwriting the existing data)
- Profit. Data is instantly queryable and tools such as Google Data Studio / Looker integrate easily, making Dashboards a click away and long waits for query results a thing of the past.
We now fit our goals very well:
- Anyone can run queries or create dashboards from BigQuery (we’re using a tool on top of BigQuery for this so no SQL is required).
- The data can be queried using standard SQL or using our new business intelligence tool (developers are no longer responsible for this). Everything runs pretty much instantly (we don’t have petabytes of data after all)
- The data going into BigQuery is under our control, we only insert what we need (i.e. no plain text, no names, no emails) and we can restructure it to make it easier to analyze later.
In fact, the only custom code is our little Java app for transforming the data. The beautiful thing about this is, all developers have access to the Github repo. If someone wants to add a new field to the Data Warehouse, they push a change to the repo, it’s automatically built overnight and the data will be available the next day (or at the push of a button without interruption). You will also notice that we are aggregating data from our various data centers. This is something we could never do when querying individual production databases.
Conclusion
It’s been a few months since we started using our new Data Warehouse in production. We now have a dedicated Business Intelligence Analyst who has built out tens of dashboards and answered hundreds of data questions that would previously have taken days of developers time (if they ever made it to the top of the pile). As a result, we’re able to make better decisions about what to focus on when building our product.
We won’t stop working on the data here though, we’re planning to get as much data into the Data Warehouse as possible. From anonymized CRM data to clickstream data, we want to connect as many sources as possible to get the best possible picture of how our customers behave and what their needs are. We’re also working to optimize the import process. We’d love to have near real-time updates to the data so we can make fast decisions as a company. Watch this space.
Further reading:
https://cloud.google.com/solutions/bigquery-data-warehouse